
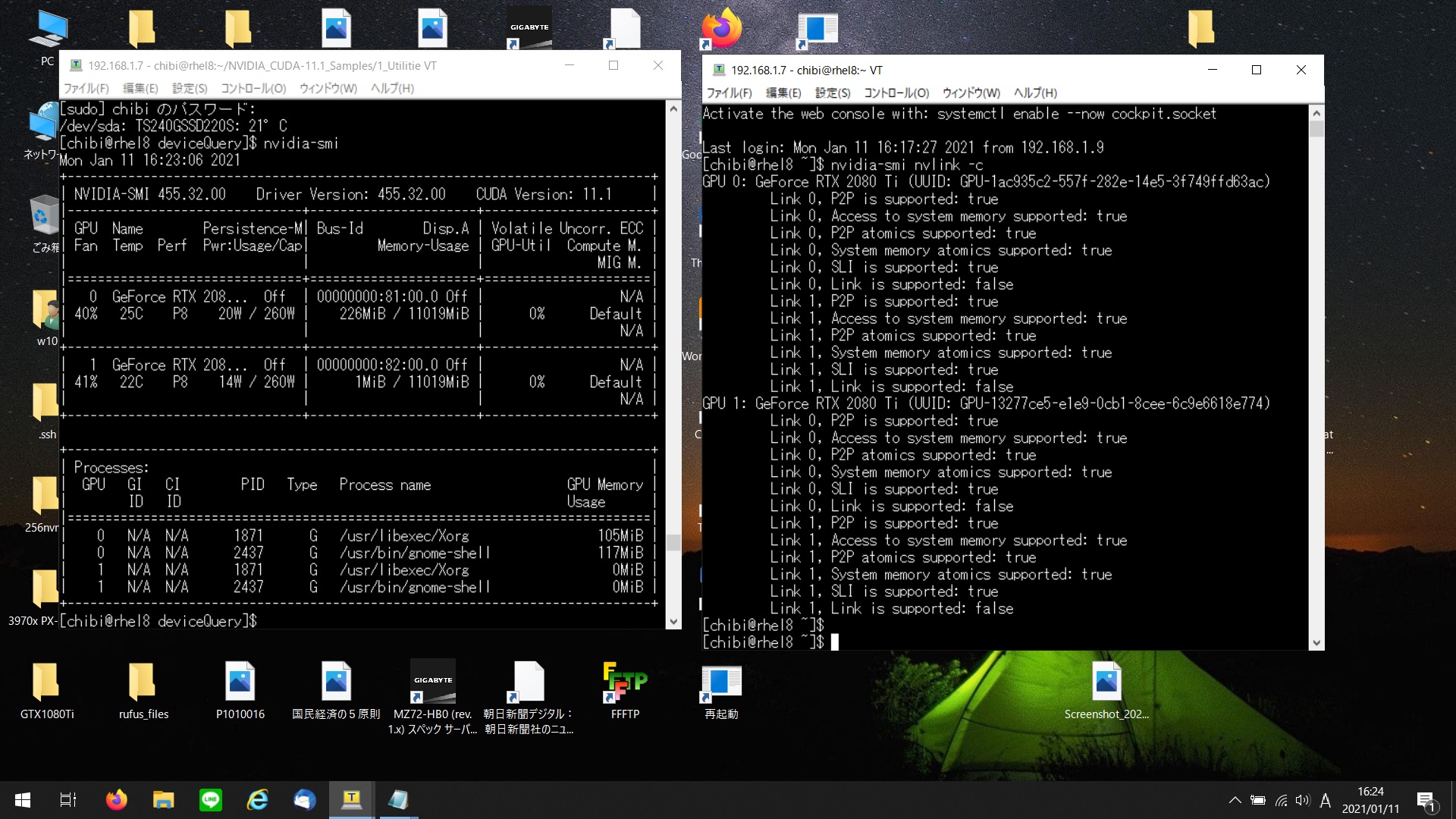
[chibi@rhel8 simpleP2P]$ ./simpleP2P
[./simpleP2P] – Starting…
Checking for multiple GPUs…
CUDA-capable device count: 2
Checking GPU(s) for support of peer to peer memory access…
> Peer access from GeForce RTX 2080 Ti (GPU0) -> GeForce RTX 2080 Ti (GPU1) : Yes
> Peer access from GeForce RTX 2080 Ti (GPU1) -> GeForce RTX 2080 Ti (GPU0) : Yes
Enabling peer access between GPU0 and GPU1…
Allocating buffers (64MB on GPU0, GPU1 and CPU Host)…
Creating event handles…
cudaMemcpyPeer / cudaMemcpy between GPU0 and GPU1: 43.54GB/s
Preparing host buffer and memcpy to GPU0…
Run kernel on GPU1, taking source data from GPU0 and writing to GPU1…
Run kernel on GPU0, taking source data from GPU1 and writing to GPU0…
Copy data back to host from GPU0 and verify results…
Disabling peer access…
Shutting down…
Test passed
[chibi@rhel8 simpleP2P]$
[chibi@rhel8 deviceQuery]$ ./deviceQuery
./deviceQuery Starting…
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 2 CUDA Capable device(s)
Device 0: “GeForce RTX 2080 Ti”
CUDA Driver Version / Runtime Version 11.1 / 11.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 11019 MBytes (11554324480 bytes)
(68) Multiprocessors, ( 64) CUDA Cores/MP: 4352 CUDA Cores
GPU Max Clock rate: 1635 MHz (1.63 GHz)
Memory Clock rate: 7000 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 5767168 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 129 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 1: “GeForce RTX 2080 Ti”
CUDA Driver Version / Runtime Version 11.1 / 11.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 11019 MBytes (11554717696 bytes)
(68) Multiprocessors, ( 64) CUDA Cores/MP: 4352 CUDA Cores
GPU Max Clock rate: 1635 MHz (1.63 GHz)
Memory Clock rate: 7000 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 5767168 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 130 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
> Peer access from GeForce RTX 2080 Ti (GPU0) -> GeForce RTX 2080 Ti (GPU1) : Yes
> Peer access from GeForce RTX 2080 Ti (GPU1) -> GeForce RTX 2080 Ti (GPU0) : Yes
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.1, CUDA Runtime Version = 11.1, NumDevs = 2
Result = PASS
[chibi@rhel8 deviceQuery]$
AMD EPYC 7302P 16-Core Processor Red Hat Enterprise Linux release 8.3 RTX2080Ti x2 CUDA 11.1 simpleP2P p2pBandwidthLatencyTest bandwidthTest deviceQuery